6 minutes
My First Generative AI
Introduction
This blog introduces my experience writing my first generative AI app.
I set out to use AI to assist in finding the right assignee for a task in my company’s task management system. As we have a distributed architecture, it can be challenging to know where to send tasks to be completed. Often, tasks will hop around a few teams before reaching the correct team - this can be frustrating for people needing their tasks resolved, and it can be distracting for teams triaging tasks if they belong outside their queue.
Caveat
I am by no means an expert. What I outline here is the best solution I found to this problem. I have tried to understand all the components as best I can, but this field is vast and complex. Feedback on improvements is very welcomed.
Scenario
We use ClickUp (Jira alternative) for our team-level task management. In its simplest form, it is a to-do list for teams that allows you to assign one or more assignees. You can create workflows such as todo, in progress and done. When the assignee starts a task, they transition it to in progress, and once complete, they transition it to done. When people want a task completed or need support, they raise a ticket and put it in the correct queue; as mentioned above, this can be challenging to determine.
Proprietary Data
Most teams use ClickUp and have historical data about what tasks have been completed and by whom, so this was a great dataset to support the task. LLMs don’t know about this data because it is confidential. We have a mechanism called embeddings to train public models with proprietary data, which I will explain next.
Because I used OpenAI for this proof of concept, I only exported the headers for the CSV and generated the data myself. I wanted to avoid training the model on company data. Alternatively, I could have used a private model such as Llama 2, which would have allowed me to use real data locally.
loader = CSVLoader(file_path="data/completed_tasks.csv")
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
This code loads text data from a CSV file, splits it into smaller chunks, and generates embeddings for each chunk using the OpenAI GPT-3 language model. This can be useful for text classification, clustering, or similarity search tasks.
Embeddings
In the context of large language models, embeddings are numerical representations of words or tokens in a continuous vector space. These vector representations capture semantic and syntactic information about the words, allowing the model to understand and generalise patterns in language.
The embeddings are generated using OpenAI with LangChain and stored in a Vector Store.
embeddings = OpenAIEmbeddings()
Vector Store
The options in this area have blown up in the past 12 months, but I opted to use FAISS as it had a CPU option, and I could run it locally for this small project. You can learn more about vector stores here
db = FAISS.from_documents(docs, embeddings)
The code uses the FAISS library to create an index for similarity search.
The FAISS.from_documents method creates an index for the given documents and embeddings using the FAISS library. This index can be used to perform similarity search by vector, which means that given a query vector, the index can quickly find the database documents most similar to the query.
Similarity Search
I was surprised to learn that the LLM isn’t used in the similarity search part of the process. In this part of the application, we pass our query to the similarity search, an implementation unique to the Vector Store. The store then determines the best fit and returns the documents.
embedding_vector = embeddings.embed_query(query)
docs = db.similarity_search_by_vector(embedding_vector)
docs
Returns:
'Task ID: ktc9f4\nTask Name: A random JavaScript task\nAssignee: [John Appleseed]\nDue Date: Monday, August 2nd 2021\nPriority-Assigned (drop down): Medium\nReport/Finder Source (short text): test\nFix Date (date):'
The similarity search algorithm used above is a vector similarity search. Specifically, the similarity_search_by_vector method of the db object searches documents in the database with embedding vectors similar to the vector generated for the query. You can read about the FAISS similarity search here.
LLM
Now that we have retrieved the document that is the best fit, we use an LLMChain to connect a PromptTemplate to a language model. The LLM is good at taking unstructured data as input and extracting the useful parts.
Here’s what I did:
query = "Who should I assign javascript tasks to?"
prompt_template = "Given the following information, what is the best course of action? Leave out information about due date, priority and report/finder along with fix date.\n\n{context}\n\n{query}"
prompt = PromptTemplate(template=prompt_template, input_variables=["context", "query"])
llm_chain = LLMChain(prompt=prompt, llm=OpenAI(temperature=0))
llm_chain.predict(context=docs[0].page_content, query=query)
First, we have a query (the same one used by the similarity search) asking where I should send Javascript-based tasks. A PromptTemplate object is created with a template string that includes context and query variables placeholders.
Then, an LLMChain object is created with the PromptTemplate and an OpenAI object that provides the language model to use. The temperature parameter is set to 0, meaning the language model will always generate the most probable output.
Finally, the predict method of the LLMChain object is called with the context and query variables as input. This generates text based on the language model and the given prompt.
Returns:
'\n\nThe best course of action would be to assign the task to John Appleseed, as they have already been assigned the task. If John is not available, then you should assign the task to someone else who is qualified to complete the task.'
Architecture
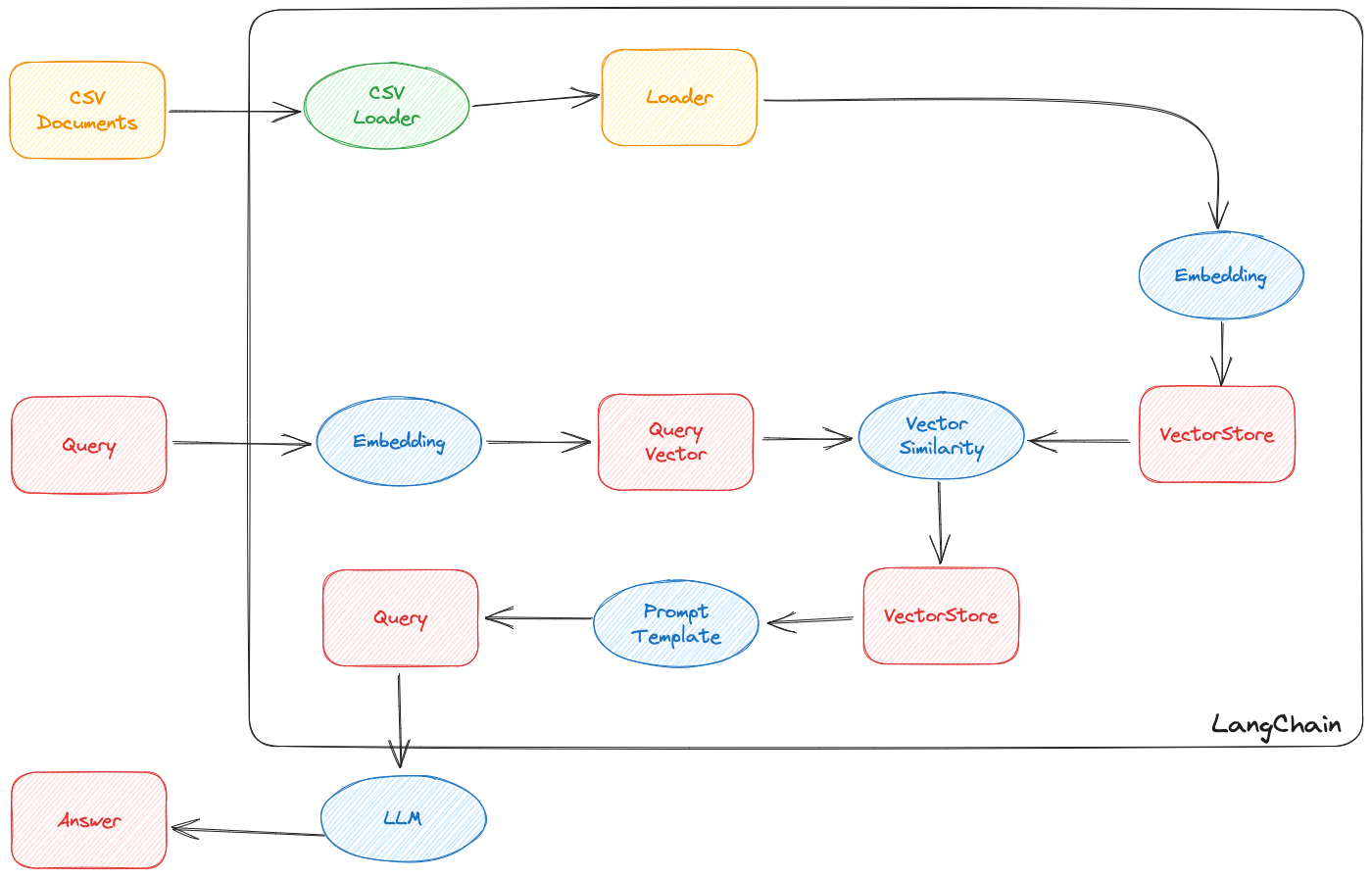
Improvements
Dont use assignee In reality, we rarely want to assign tasks to individuals. Instead, the preferred approach would be to assign a team or create the item on the squad’s backlog. The problem here is that the tasks are often moved from the backlog and put into a sprint. If I used the list information, it’s highly probable it would tell me to put the task in a closed sprint.
Use descriptions for more context Sadly, you don’t get the long-form description when you export your workspace data from ClickUp. As a result, the similarity search is performed in a smaller context. This would greatly reduce the accuracy of the answer, as it will be based on a terse title rather than a detailed description.
Conclusion
Creating my first generative AI application has been enlightening and challenging. The primary objective was to streamline the task assignment process within our company’s task management system. The application leverages the power of large language models and embeddings to perform similarity searches, thereby suggesting the most suitable assignee for a given task.
While the proof of concept was successful, it’s important to acknowledge the limitations and areas for improvement. For instance, the current model focuses on individual assignees, whereas a more practical approach would be to assign tasks to teams. Additionally, the absence of long-form descriptions in the exported workspace data from ClickUp limits the context available for similarity searches, potentially affecting the accuracy of the model’s recommendations.
The technology stack used, including OpenAI for embeddings and FAISS for vector storage and similarity search, proved robust and efficient for this small-scale project.
As AI continues to evolve, so will the capabilities and applications of generative models. This project serves as a stepping stone, offering insights into the complexities and possibilities of leveraging AI for organisational efficiency.
ai langchain llama faiss howto
1231 Words
2023-08-29 20:58 (Last updated: 2026-01-05 11:50)
e6c7ad7 @ 2026-01-05