3 minutes
Terraform Layered Composition
I discovered a new trick with Terraform, which helps us better structure our infrastructure as code. As the title suggests, it’s called layered composition. I’m a big advocate of the innersource movement, and I think it’s a good idea to have most things visible. However, there are some things people just don’t need to worry about. Take, for example, how subscriptions are created within an Azure account. For the most part, as a DevOps engineer, that’s a detail I don’t need to know. My concern is that I have a subscription, It has the service principals I need and the Azure team are monitoring it. To go a layer deeper, let’s explore development environments. Developers should understand their runtime environment and how it’s structured. Still, they needn’t concern themselves with the minutiae like what size nodes are assigned to their environment. Typically, with Terraform, you would structure your projects with environments; int, QA, staging and prod. Your project structure may look something like this:
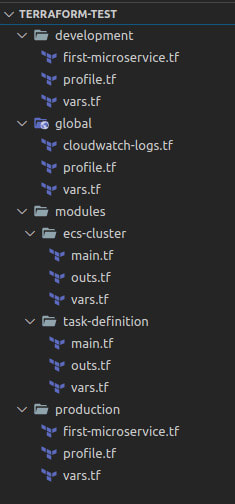
This is helpful because everything is all in one place and you can cross-reference resources efficiently. However, as the number of users grows, the amount of churn on the repository grows with it. This can lead to problems with integration, and without a solid test pipeline to usher your changes through, you have an excellent chance of borking complete environments. Much like the Microservice movement, the solution here is to break things down into smaller chunks.
Layering is one way to decompose a much larger project into multiple smaller projects with clear boundaries. Layering also helps us understand our upstream dependencies, and composition then allows us to reference those dependencies without needing the code itself checked into our project. Let’s look at layering:
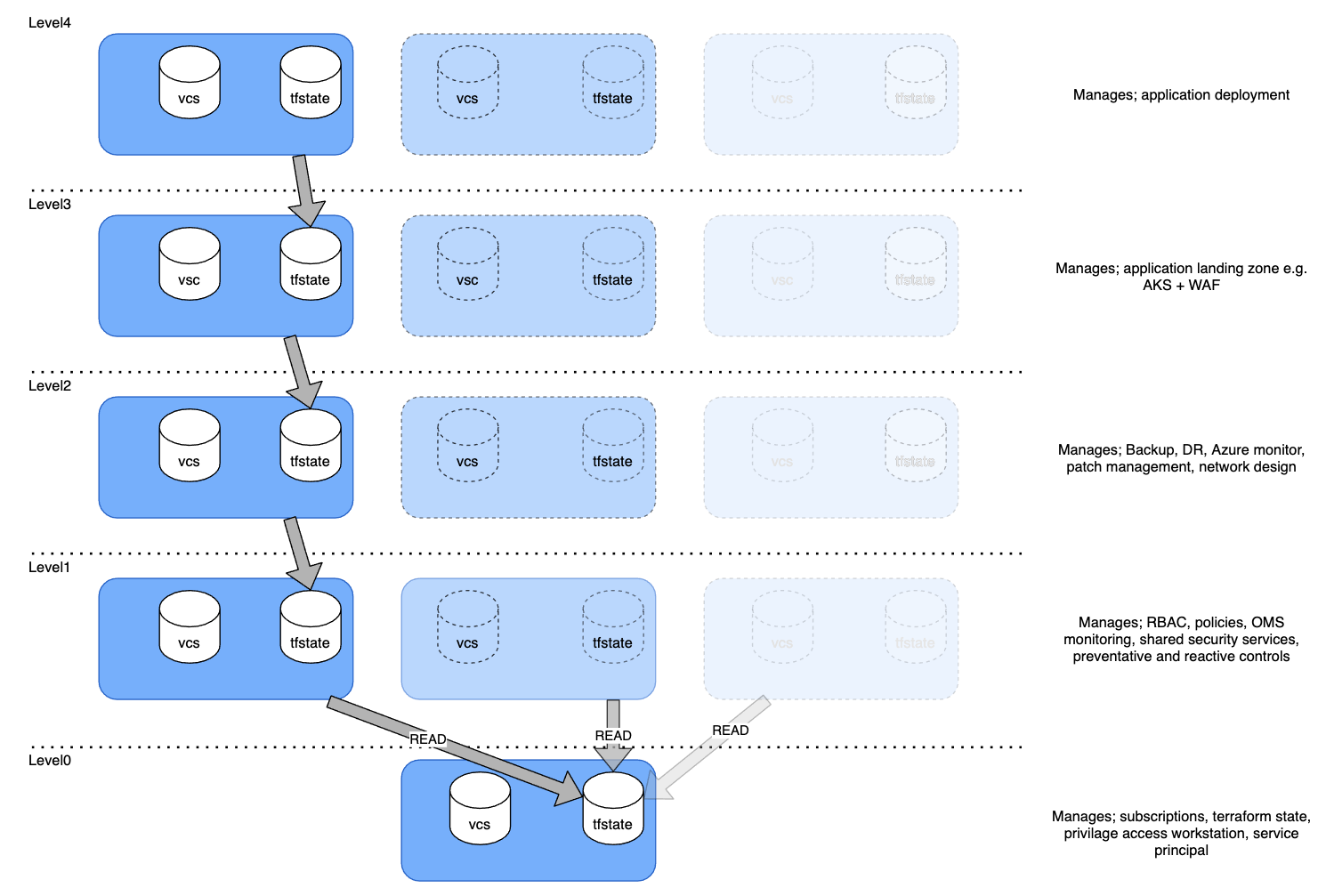
Here we see the layers follow a hierarchy which reflects most cloud topologies; subscriptions, security, networks etc. with clear separation of concerns.
Now lets wire these things together so that we can reference the resources between layers. In the code example below I’m creating a network and a resource group in the level2 project.
<!-- FILE: networking.tf -->
resource "azurerm_resource_group" "apaas" {
name = "rg-${var.prefix}-apaas"
location = var.location
tags = merge(local.common_tags, local.extra_tags)
}
resource "azurerm_virtual_network" "apaas" {
name = "vnet-${var.prefix}-apaas"
location = azurerm_resource_group.apaas.location
resource_group_name = azurerm_resource_group.apaas.name
address_space = ["10.1.0.0/16"]
tags = merge(local.common_tags, local.extra_tags)
}
resource "azurerm_subnet" "apaas" {
name = "snet-${var.prefix}-apaas"
virtual_network_name = azurerm_virtual_network.apaas.name
resource_group_name = azurerm_resource_group.apaas.name
address_prefixes = ["10.1.0.0/22"]
}
And in the example below, through composition, I’m referencing a level2 resource from a level3 project:
<!-- FILE: aks.tf -->
data "terraform_remote_state" "leveltwo" {
backend = "remote"
config = {
organization = "myorg"
workspaces = {
name = "leveltwo"
}
}
}
resource "azurerm_kubernetes_cluster" "apaas" {
name = aks-"${var.prefix}-apaas"
location = data.terraform_remote_state.leveltwo.azurerm_resource_group.apaas.location
resource_group_name = data.terraform_remote_state.leveltwo.azurerm_resource_group.apaas.name
dns_prefix = aks-"${var.prefix}-apaas"
default_node_pool {
name = "user"
vm_size = "Standard_D2_v3"
node_count = 2
availability_zones = ["1", "2"]
enable_auto_scaling = true
min_count = 1
max_count = 4
vnet_subnet_id = data.terraform_remote_state.leveltwo.azurerm_subnet.apaas.id
}
tags = merge(local.common_tags, local.extra_tags)
}
There’s a lot to like about this design, but for me, I really like that it allows me to keep projects small so that comprehension stays high.
infrastructure terraform howto
516 Words
2020-10-29 14:53 (Last updated: 2026-01-05 11:50)
e6c7ad7 @ 2026-01-05